It has only been a few days since Anthropic announced their new model Claude Sonnet 4.5, and I wanted to see for myself if the hype matches reality. Instead of reading benchmarks, I opened Cursor and ran some coding tests to feel it as an end user.
My goal with this test wasn’t to cover every possible case or measure the model’s intelligence. I just wanted to try a few real-world tasks that I deal with in my day-to-day work, and see how the models do in terms of code quality, speed, and output. This is purely a personal experiment, not an academic or comprehensive benchmark. You might see it differently, and that’s fine, I just want to give you a quick snapshot before you run your own tests.
I decided to test two key aspects of a developer’s workflow:
- Generating code for a new feature from scratch
- Generating a test suite for an existing function
I put three of the top coding models to the test: Anthropic’s new Claude Sonnet 4.5, OpenAI’s GPT-5 Codex, and xAI’s Grok Code Fast 1.
Test 1: Generating a New App
For the first test, I wanted to see how well each model could handle a greenfield project, a common starting point for any new idea.
The Prompt
“Generate a complete, production-ready React application using Vite and Tailwind CSS. The application should be a responsive image gallery. It should fetch images from a placeholder API (like
picsum.photos), display them in a grid, and open a larger view in a modal when an image is clicked. Include basic styling for a clean, modern look and feel. Structure the code into logical components and provide instructions for running the project.”
Impression
Claude Sonnet 4.5
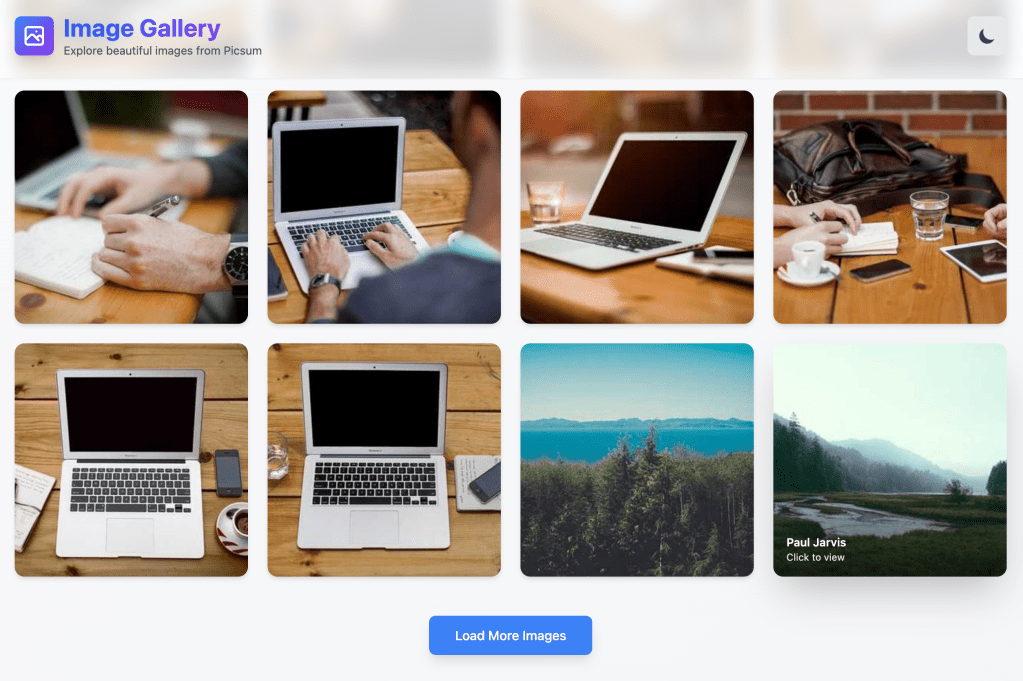
- This was impressively fast, completing the entire task in about a minute. It presented a clean, clear to-do list that was easy for an engineer to follow.
- It was built with JavaScript and JSX, ran perfectly on the first try, styling was ok.
- The code structure and component splitting were clean, simple, and exactly what I was looking for.
- It even included a dark mode, which I hadn’t requested.
- This was my favorite output of the three.
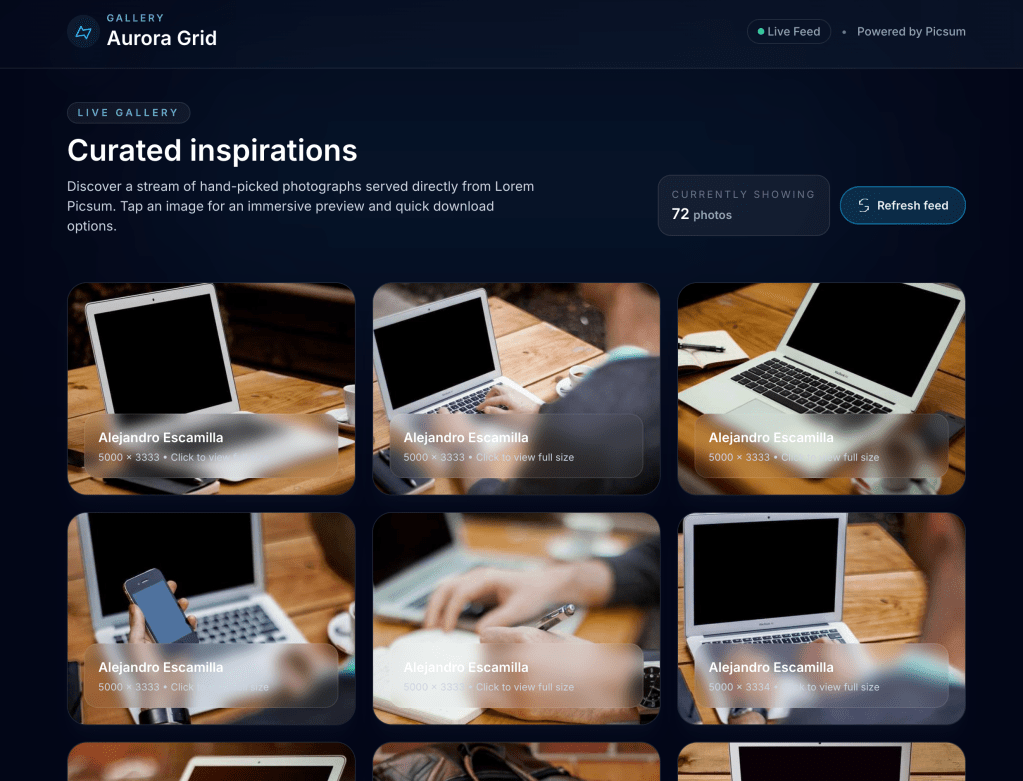
GPT-5 Codex
- This model took a more methodical, but much slower approach. The process required me to manually confirm a series of scaffolding CLI commands, and the whole task took about a few minutes.
- The final app also use JavaScript and JSX, it was fully functional on the first try.
- The styling was better than Claude Sonnet 4.5‘s.
- It also added an infinity scrolling feature I didn’t ask for, which was great.
- While the code structure was good, it felt a bit overcomplicated for my simple request.
- The output was high-quality, but the process was a bit cumbersome.
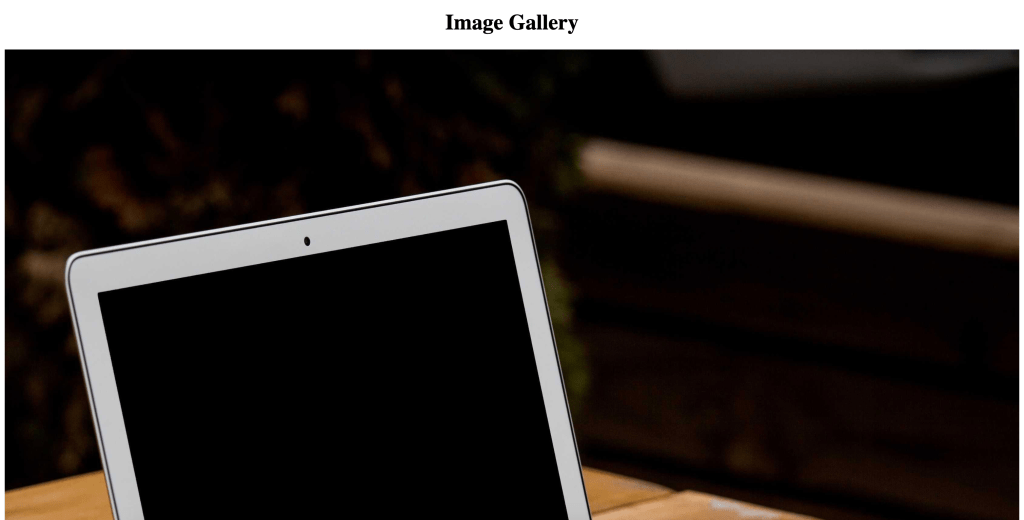
Grok Code Fast 1
- The experience here was similar to GPT-5 Codex, taking a few minutes to complete.
- The app, which it generated using TypeScript, did start on the first try, but the functionality was broken and the CSS was messy.
- The code structure and component splitting weren’t good, and I was not a fan of the code it generated.
- The cost is significantly lower compared to the other models.
Output
Claude Sonnet 4.5
GPT-5 Codex
Grok Code Fast 1
Output: Main screen
Output: Image modal

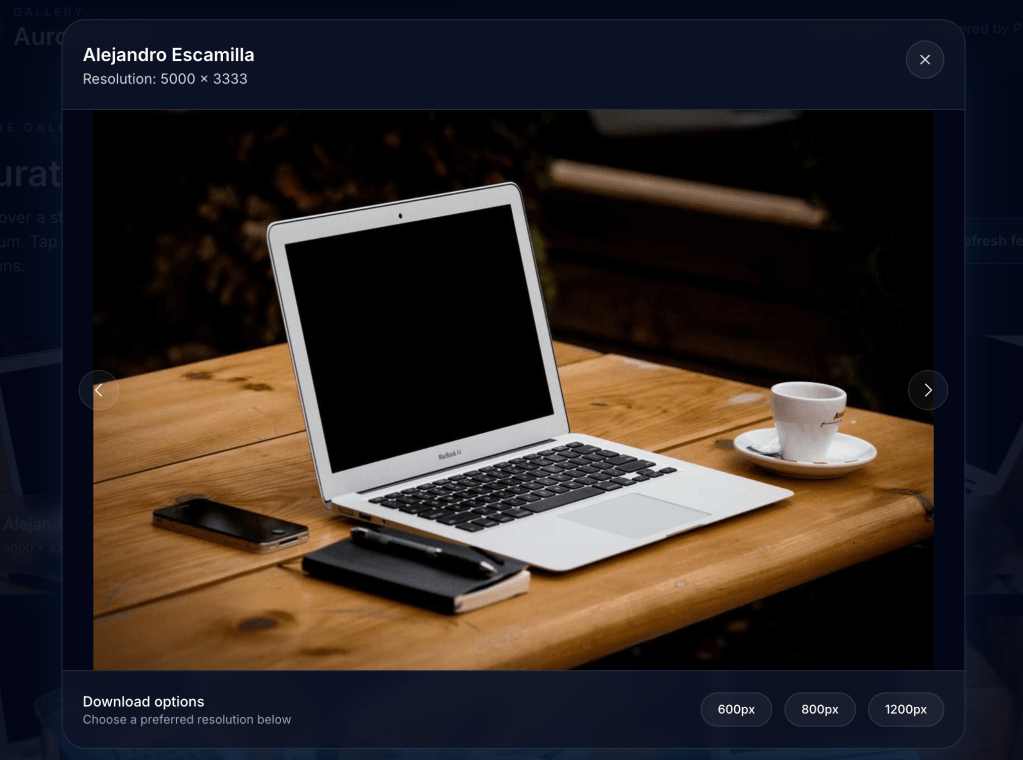
Could not work as expected
Detail comparision
Generated Todo list
Claude Sonnet 4.5
GPT-5 Codex
Grok Code Fast 1
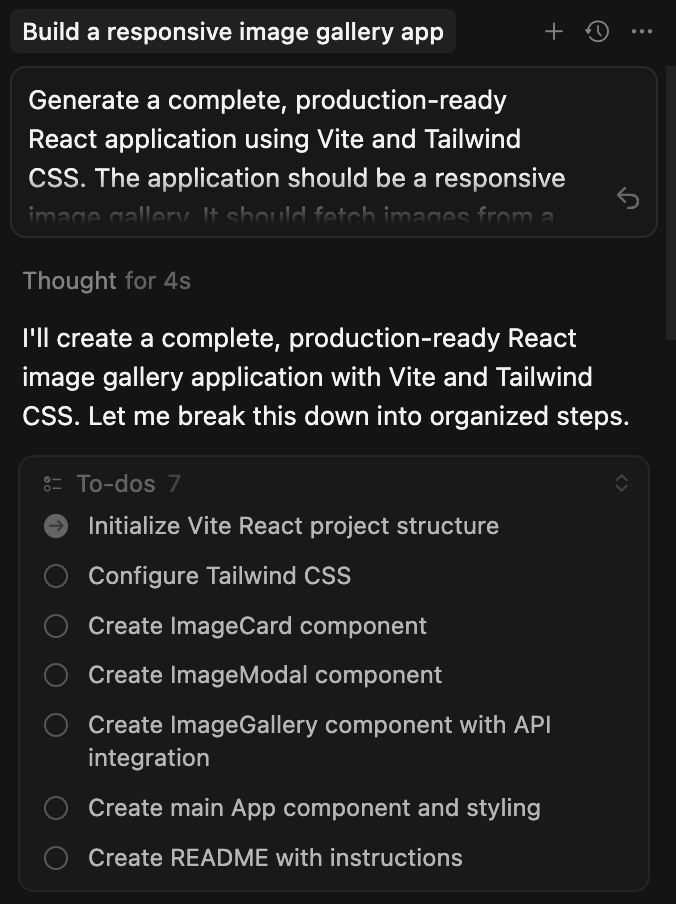

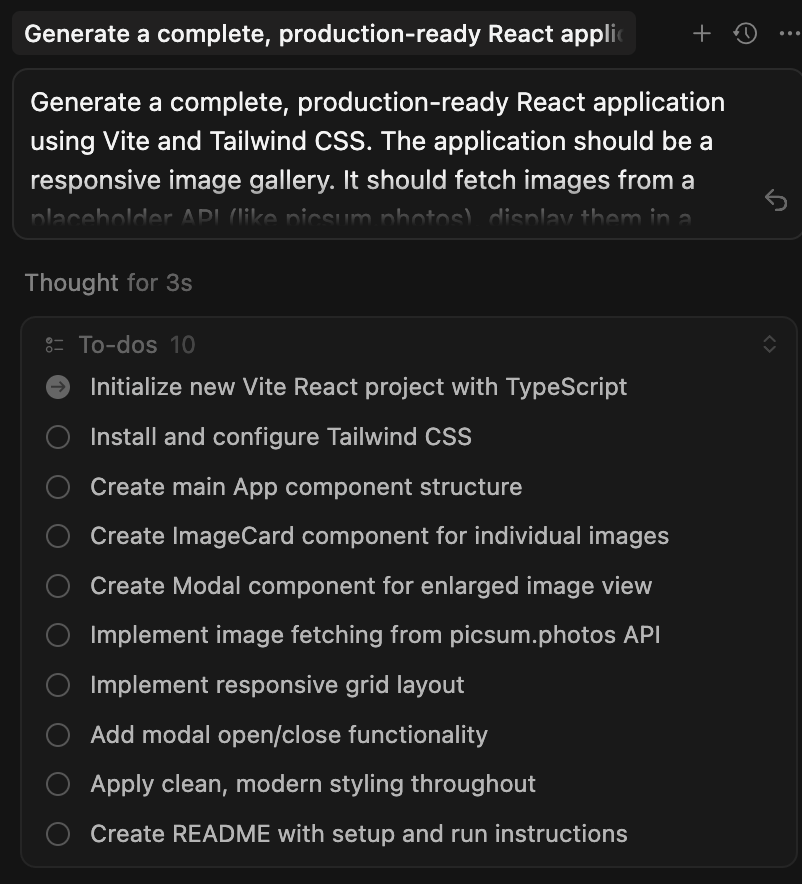
Claude Sonnet 4.5 delivers the most concise and focused plan.
- Aligned tightly with the prompt, it sticks to the core requirements.
- Structured around three main components: ImageCard, ImageModal, and ImageGallery.
- Smartly groups related tasks (ex: building the gallery and API integration together).
- No unnecessary features or extra technologies.
- Easiest to read at a glance, with a straight path to the final output.
GPT-5 Codex offers the most feature-rich, production-oriented approach.
- Goes beyond the prompt by adding pagination, loading/empty states, and polished styling.
- Considers usability with keyboard/escape support.
- Separates logic via an image fetch hook and types, showing modern React best practices.
- Treats the task more like building a complete webpage than just a component set.
Grok-code-fast-1 is the most detailed and step-by-step.
- Breaks everything into 10 small tasks, covering setup and functionality separately.
- Explicitly chooses Vite + React + TypeScript from the start.
- Translate the prompt into coding actions.
At this stage, GPT-5 Codex is the most thoughtful, though it also introduces more complexity in the implementation.
If I had to choose, Claude Sonnet 4.5 best matches my preferred style of working. Grok Code Fast 1 provides a clear step-by-step setup, but lacks an overall implementation structure.
Folder structure & components breakdown
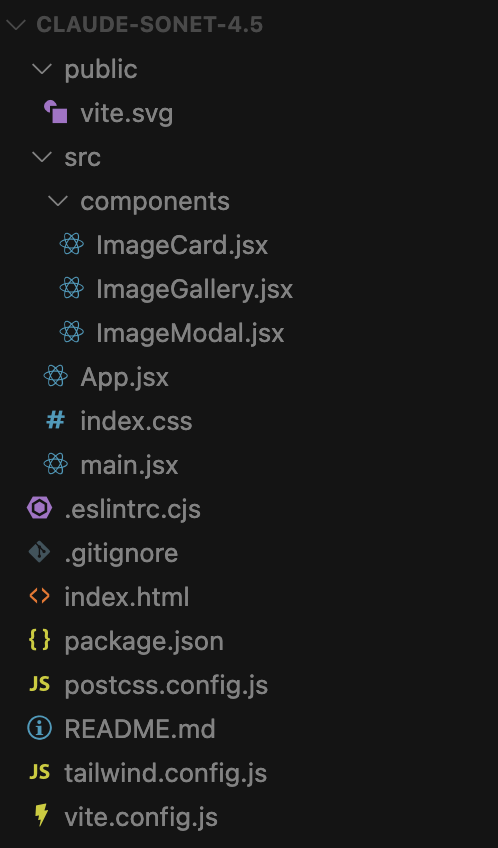
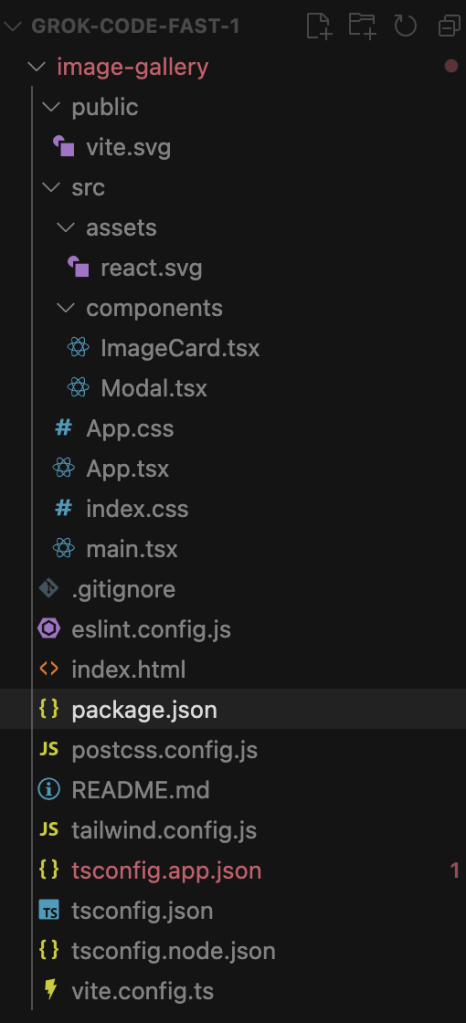
Claude Sonnet 4.5‘s structure is the simplest and most direct of the three. It’s a classic JavaScript-based React project.
- It created three components:
ImageCard.jsx,ImageGallery.jsx, andImageModal.jsx. Simple and good enough structure. - It created
ImageGallery.jsxas a “container” component to manage the layout of the image cards, which is a good structure.
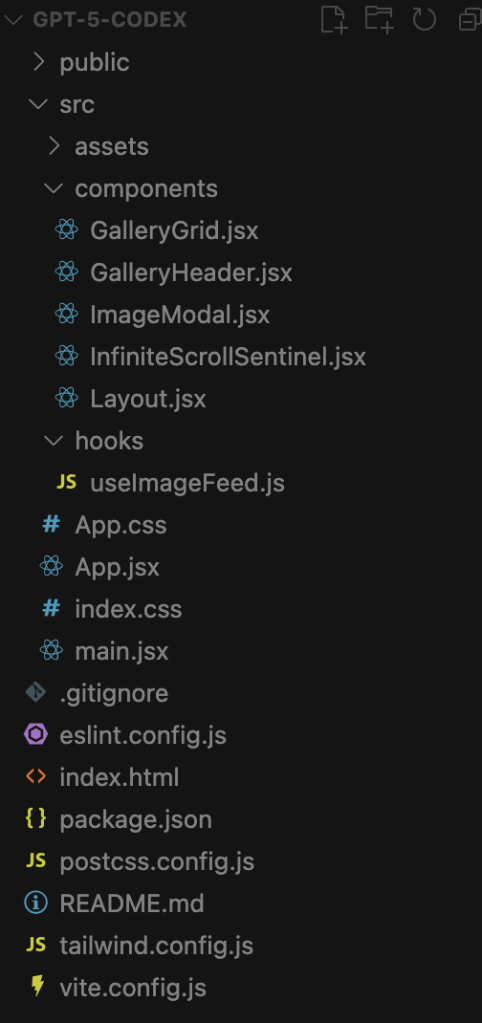
GPT-5 Codex‘s structure is the most sophisticated and demonstrates an understanding of advanced React patterns for building larger, more complex applications.
- It created a
hooksfolder containing a custom hook:useImageFeed.js. It separates the application’s logic (like fetching data, managing state, etc.) from the UI components. This makes the logic and the components easier to test and reuse. - The
componentsdirectory is much more detailed.
Grok Code Fast 1‘s structure is clean and modern for TypeScript & React development.
- The components folder contains two core UI pieces: ImageCard.tsx and Modal.tsx. This is a common way to organize UI elements.
- The core logic is likely bundled within App.tsx, making it less modular.
- The structure is less organized and clean compared to the others.
After reviewing the code, I found that the structure from GPT-5 Codex is robust enough for a production environment.
In contrast, the code from Claude Sonnet 4.5 is simple and clean, making it an excellent starting point for a developer. I wasn’t a fan of the structure from Grok Code Fast 1 in this test.
I’d consider it a tie between GPT-5 Codex and Claude Sonnet 4.5, as they both excel in different areas.
Line of Code
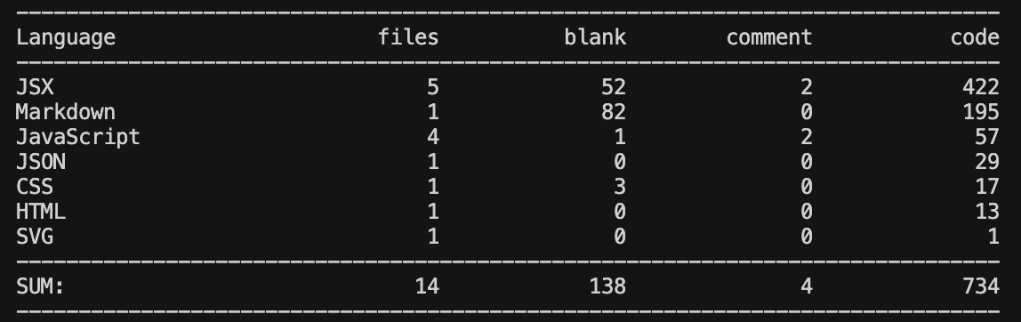
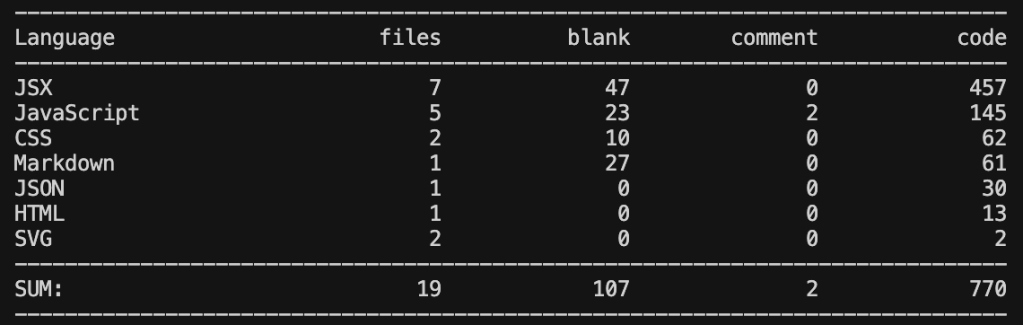
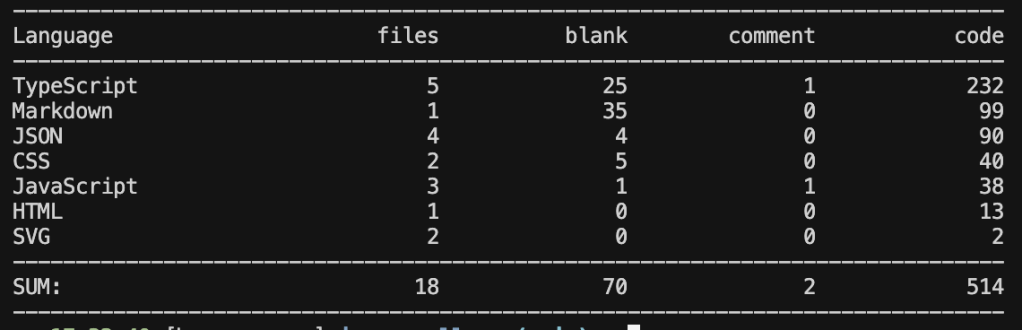
Claude Sonnet 4.5
- Implementation is leaner than GPT-5 Codex but heavier than Grok Code Fast 1.
- Best documentation coverage.
- It makes me feel a balance between implementation and documentation.
GPT-5 Codex
- Heaviest on real application logic, so we can understand that it is the most feature-rich implementation.
- Docs are light.
Grok Code Fast 1
- Much lighter real app logic compared to GPT-5 Codex and Claude Sonnet 4.5, explain why the functionalities didn’t work.
- Docs are better than Codex.
In summary, both GPT-5 Codex and Claude Sonnet 4.5 performed well in this test.
Personally, I value speed and simplicity, so I’d choose Claude Sonnet 4.5 for execution. However, for the planning phase, I’d lean on GPT-5 Codex because of its thoroughness.
Test 2: Writing Tests
For the second test, I wanted to see how each model would handle writing tests for a function, the kind of everyday task engineers deal with regularly.
The Prompt
Generate a Jest test suite with edge cases for this function. Put the file in a util folder.
function divide(a, b) { return a / b; }
Results
Claude Sonnet 4.5
GPT-5 Codex
Grok Code Fast 1
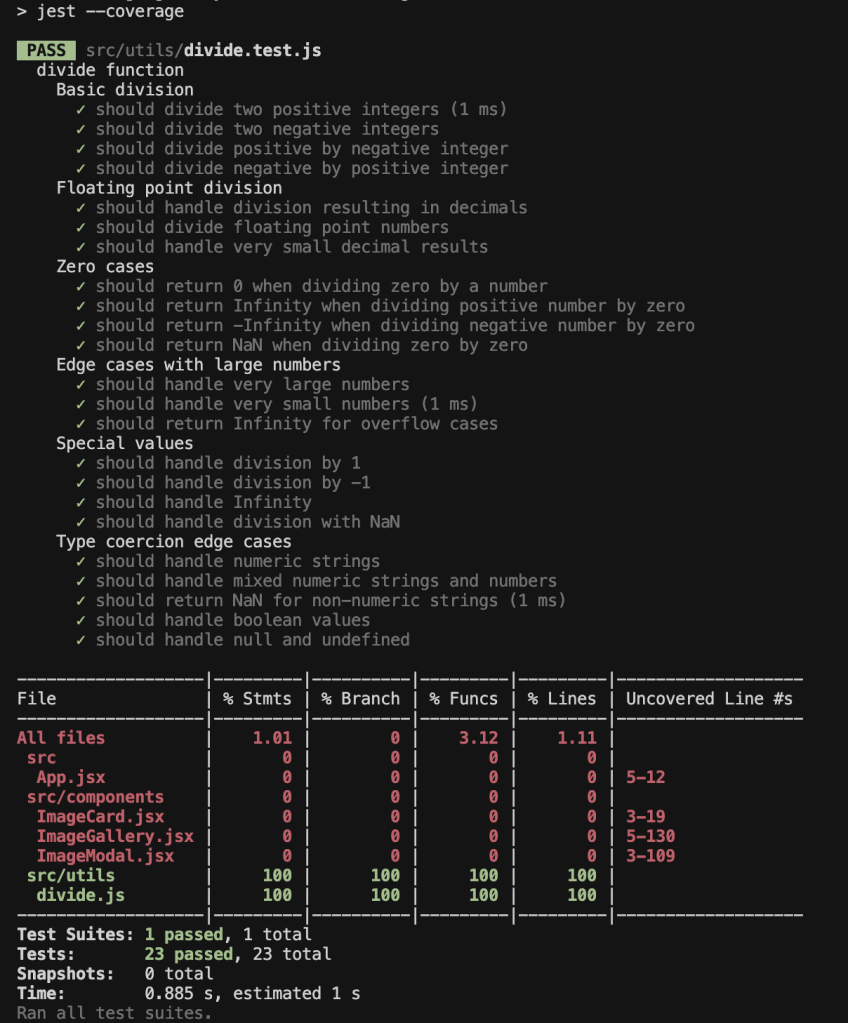
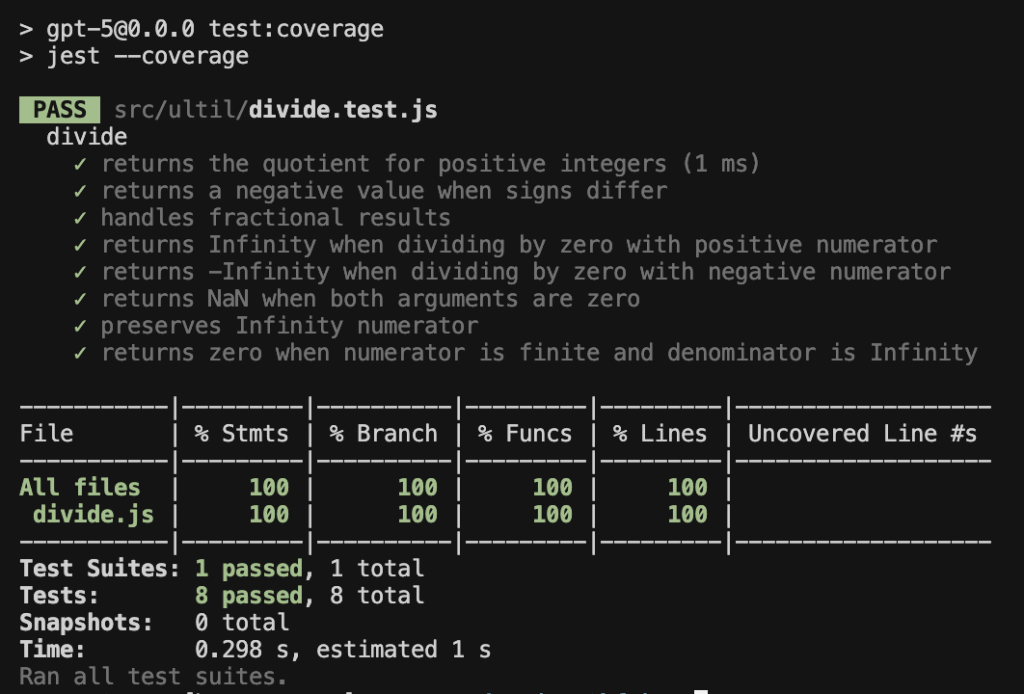
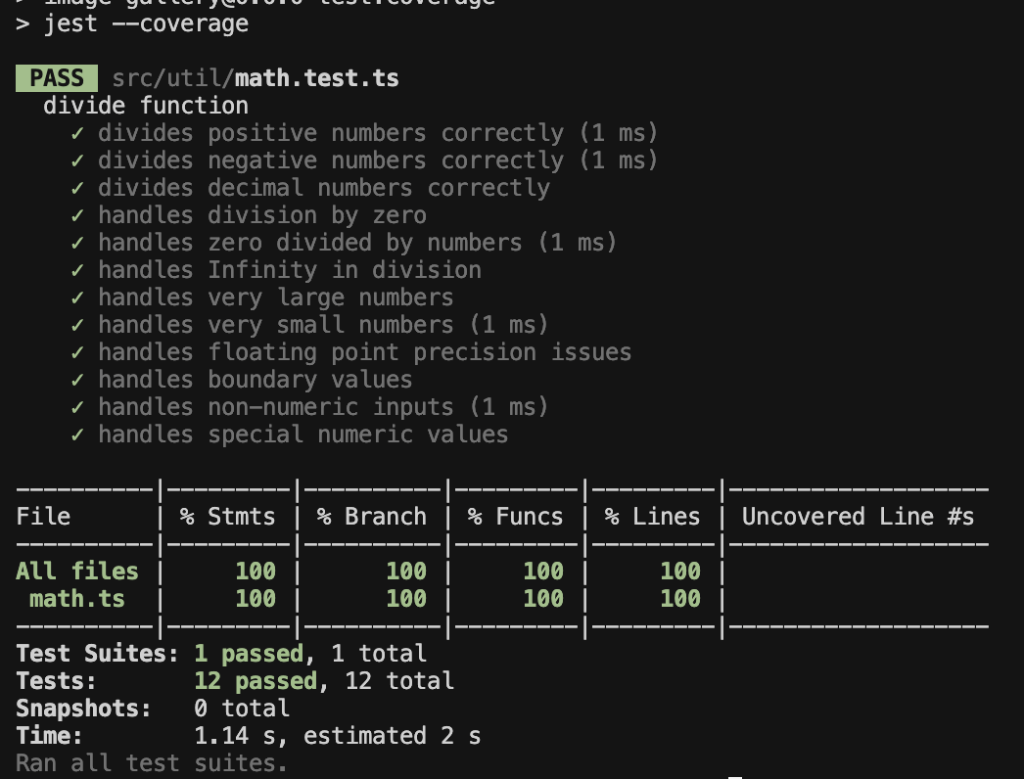
Claude Sonnet 4.5
- Fast to generate the test script and asked about the test setup.
- After completing the test setup, it auto ran and double-checked coverage.
- Produced 23 test cases covering division by zero, floats, negatives, and large numbers. Very detailed and thorough.
- Covers all from Codex + Grok
- Adds more categories:
- Floating point division
- Edge cases with overflow
- Type coercion edge cases (numeric strings, booleans, null, undefined)
- Limitations:
- More verbose, harder to maintain.
- Some cases may be unrealistic for real-world usage.
GPT-5 Codex
- Quick and direct, produced 8 test cases.
- Positive/negative integers
- Fractional results
- Division by zero (Infinity, -Infinity, NaN)
- Special handling with Infinity numerator
- Zero result with Infinity denominator
- Asked about setup but didn’t check coverage.
- Got the basics right, but shallow.
- Style is concise, direct, and structured, ensuring correctness without redundancy.
- Coverage is ok, but scope is narrower compared to the other two models.
- May miss some rare edge cases like non-numeric inputs or type coercion.
Grok Code Fast 1:
- Slower, required setup commands first, similar to the first test. I need to manually approve a lot of CLI commands to do the test setup.
- The good thing is that it only needs 1 prompt to complete everything, from setup to generating test cases.
- Ended with 12 test cases. Solid coverage but no coverage check.
- Very large numbers
- Very small numbers
- Floating point precision issues
- Boundary values
- Non-numeric inputs
- Special numeric values (NaN, Infinity, etc.)
- Organized in a clean scenario-driven approach, making it easy to reason about what’s tested, covering realistic as well as edge inputs.
Personally, Grok Code Fast 1 offers the most practical suite for production use.
GPT-5 Codex is ideal for a lean starting point, and Claude Sonnet 4.5 is best when maximum safety and completeness are required.
Cost Comparison
Here’s how the three providers price their coding models (per million tokens):
| Model | Input Price (per 1M token) | Output Price (per 1M token) |
| Claude-sonnet-4.5 | $3.00 | $15.00 |
| GPT-5 Codex | $1.25 | $10.00 |
| Grok-code-fast-1 | $0.20 | $1.50 |
(Prices are not 100% exact; they vary depending on provider updates. You can check the latest on OpenRouter)
If cost is the biggest factor, I would consider Grok Code Fast 1, but the way I prompt will be significantly different and cost more effort.
Conclusion
After spending a good amount of time with these models, I have a clear favorite for my day-to-day coding work: Claude Sonnet 4.5. Honestly, it’s my top recommendation.
Now, if you’re trying to find a balance between cost and quality, GPT-5 Codex is a good choice. The code it writes is really polished and high-quality, and it’s more affordable to run.
But here’s the biggest takeaway for me: you don’t have to choose just one. A hybrid workflow seems like the real power.
- You could use GPT-5 Codex for the initial planning phase, since it’s so thoughtful about architecture.
- Then, when it’s time to actually write the code, switch over to Claude Sonnet 4.5 to take advantage of its raw speed and incredible thoroughness.
- And even though Claude Sonnet 4.5 generates the most comprehensive test cases, Grok Code Fast 1 felt more practical for production use, so when it comes to writing tests, Grok is not a bad choice.
I’m glad we could dive into this together. I’m really interested to hear about your own experiences as you get to know these tools!
Discover more from Codeaholicguy
Subscribe to get the latest posts sent to your email.
